
The Future of Infrastructure is Invisible
Writing code is no longer the hard part. It’s everything that happens after.


For decades, writing code was the bottleneck in software development. If you could build it, you could ship it.
That era is ending.
AI-assisted coding has fundamentally shifted where complexity lives. We can now go from concept to code in minutes, but deploying reliably at scale still takes days or weeks. The constraint has moved from creation to delivery.
More people can build software, so more software gets built. More software means more infrastructure to provision, monitor, and maintain. The operational burden compounds while our ability to manage it manually approaches its limits.
Solving this problem is the next frontier in software development.
The new bottleneck
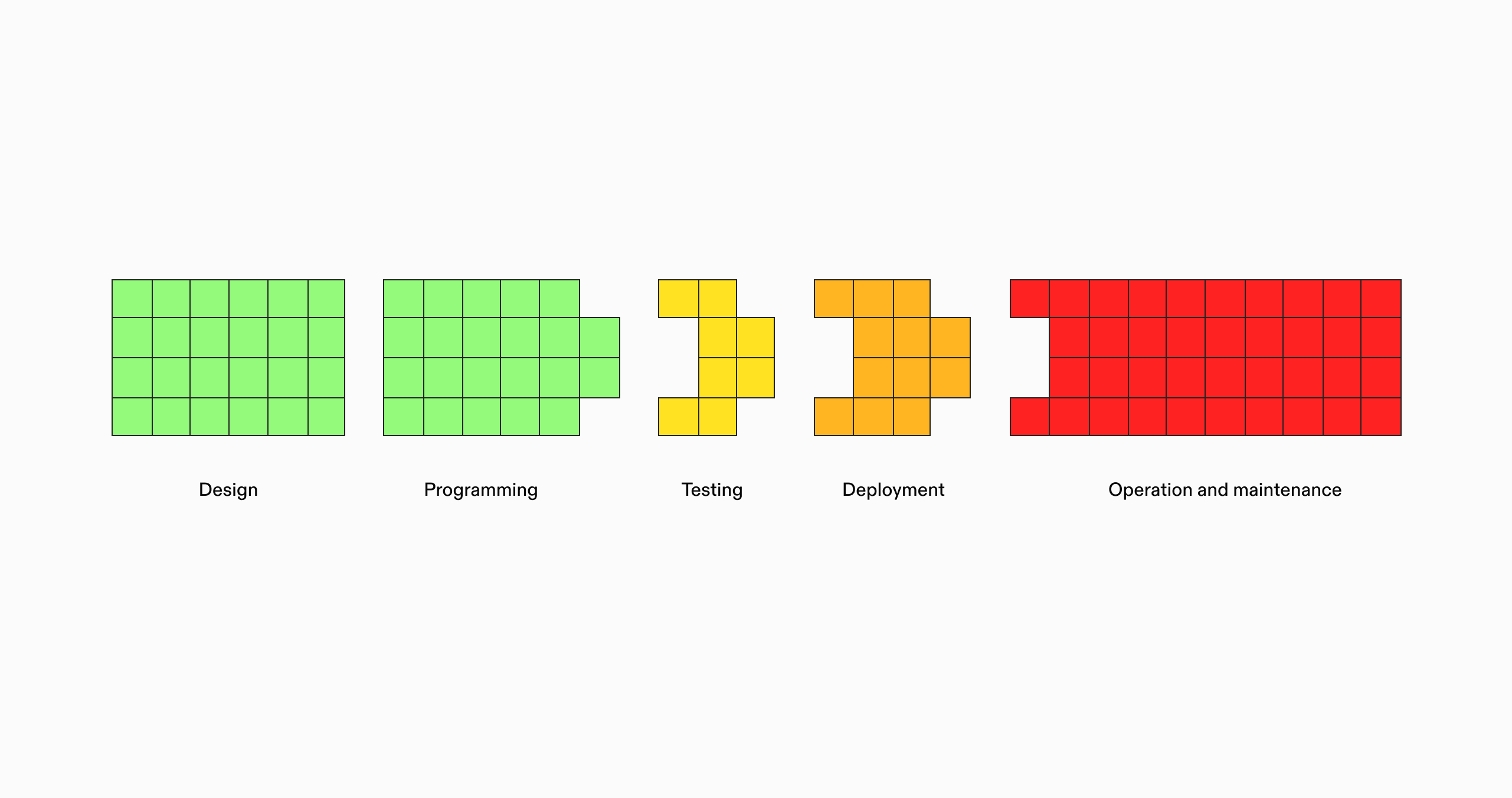
Over the past two years, we've worked with hundreds of companies across industries, from early-stage startups to Fortune 500 enterprises, to optimize their infrastructure. Through that process, we've observed consistent patterns that go beyond company size, technical stack, or industry. Four core forces drive post-deployment complexity:
Deployment has become its own discipline. Shipping code requires mastering an entirely separate skill set from writing it.
Provisioning infrastructure: servers, databases, caches, networks, and more
Setting up CI/CD pipelines to automate testing and deployment
Validating software quality in staging and development environments
Deploying to production, accounting for rollout strategies, rollback procedures, and incident response
Monitoring and maintaining application health once it's in production
Handling ongoing operational tasks like infrastructure cost management, security, and compliance
Specialization fragments knowledge. The people who understand code intent rarely manage its runtime behavior. Deployment complexity has spawned dedicated infrastructure roles: DevOps engineers, SREs, platform teams. While specialization brings expertise, it introduces friction. Developers write code that gets handed through CI/CD pipelines to infrastructure teams for production management. Context gets lost in translation.
We have more data, less clarity. Modern systems generate overwhelming volumes of information: logs, metrics, traces, incidents, tickets, Slack threads. While this data is valuable, it lives in silos across cloud providers, monitoring tools, pipelines, and communication platforms. Correlating it manually is slow, difficult, and often futile.
Intent gets buried in implementation. Business requirements disappear under layers of technical configuration. Nearly every infrastructure decision is resource-centric: servers, clusters, databases, caches. Engineers constantly translate high-level business goals into low-level configuration. When requirements inevitably change, they reverse-engineer the original intent and restart the translation process.
The complexity trap
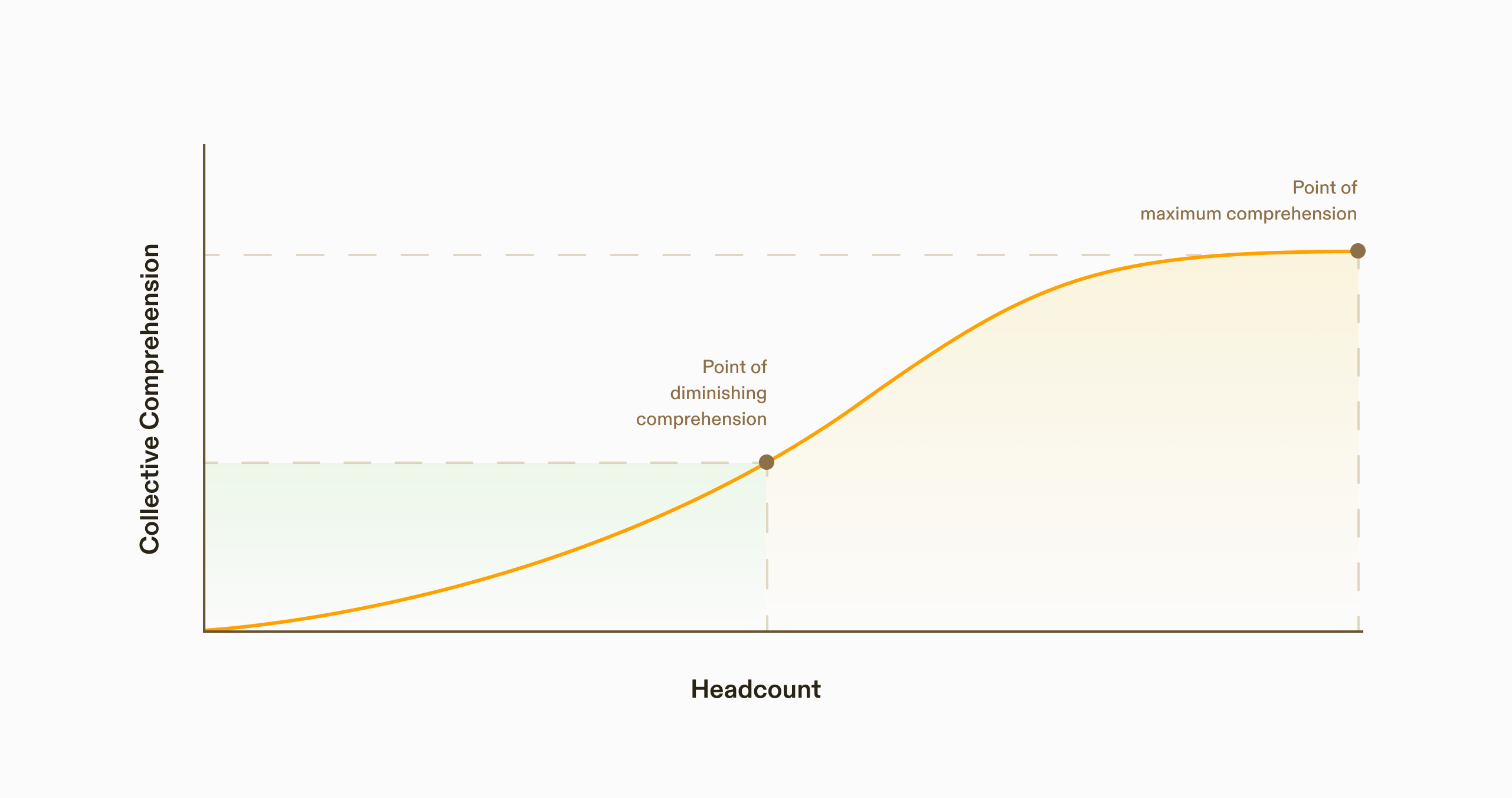
These problems reinforce each other in a vicious cycle.
Operational complexity drives specialization, creating silos that struggle to correlate data across fragmented systems. Human operators bridge the gaps through intuition and tribal knowledge, but as systems grow more complex, even specialists struggle to keep up. The cycle perpetuates.
Infrastructure isn't a resource problem—it's a complexity problem. Headcount scales linearly, but comprehension doesn't. As systems grow, context fragments, decisions get siloed, and intent gets lost in translation. Adding more people often intensifies the problem rather than solving it.
Most companies don't stagnate because they can't write code fast enough. They stagnate because managing their infrastructure and operations becomes exhausting and increasingly difficult. Teams get trapped maintaining systems instead of building what's next.
To make meaningful progress, we need to move beyond rigid, opinionated abstractions: PaaS, serverless, or otherwise. We need systems that adapt intelligently, understand developer intent and context, and evolve dynamically as business needs change.
We don't need to get better at serving infrastructure. Infrastructure needs to get better at serving us.
Why AI conquered code but not infrastructure
When AI can refactor thousands of lines of legacy code, why can't it recommend the right instance size for your workload?
This disparity reveals something fundamental about how AI interacts with different domains. LLMs and reasoning models are naturally attuned to working with code in ways they aren't with infrastructure.
Code is structured and predictable
Code is a language. Programming languages have well-defined syntax and semantics, making them natural candidates for models trained on language. LLMs, built on attention-based architectures, learn code the same way they learn prose by modeling patterns in tokens, structure, and meaning.
There's abundant high-quality training data. Millions of repositories on GitHub contain real-world code across every language, framework, and domain imaginable. This creates a rich dataset of patterns, idioms, and solutions for models to learn from.
Most code can be verified or tested. Code either works or it doesn't. You can run it, test it, and benchmark it automatically. This feedback creates straightforward validation of model outputs and tight feedback loops for improvement.
Infrastructure is contextual and dynamic
Infrastructure lacks these advantageous properties.
There's no canonical way to represent infrastructure. It's scattered across Terraform scripts, Kubernetes manifests, YAML files, custom configs, and countless other formats. There's no single source of truth that captures every aspect of how your infrastructure works.
It's inherently context-dependent and requires continuous management. What works for one company's scale, budget, or regulatory requirements can be completely wrong for another. More importantly, your own context never stops changing. Growth means scaling, tight budgets force optimization, and new features drive new infrastructure needs. Infrastructure is never truly finished because the environment it operates in continuously evolves.
You can only evaluate it at runtime. Unlike code that can be tested in isolation, infrastructure behavior emerges from the interaction of multiple systems under real load, real data, and real business conditions. A configuration that worked perfectly in staging can fail catastrophically in production due to network latency, data volume, or user behaviors impossible to replicate in testing.
This asymmetric progress isn't due to lack of motivation. Abstracting infrastructure is fundamentally harder.
But we can learn from programming's evolution. Code has gradually shifted from imperative to declarative. From telling computers how to do something step-by-step to simply describing what you want.
Infrastructure will follow the same pattern.
The future of infrastructure
We believe the future is intent-driven infrastructure.
In this model, engineers no longer configure how systems should work—they define the outcomes they want.
User uploads should work reliably from any device, anywhere
Financial data must be encrypted and auditable for SOC2 compliance
This machine learning job should complete within our monthly budget
The system translates these goals into infrastructure configurations and continuously monitors whether you're achieving them. When upload success rates drop or ML costs exceed budget, it adapts automatically, learning from your team's decisions and operational patterns.
This creates a continuous optimization loop. The system monitors whether declared outcomes are being met in real time. When constraints conflict or goals evolve, it escalates decisions to humans. As new patterns emerge, it updates its behavior.
When infrastructure is driven by high-level intent instead of configuration, it becomes invisible. The complexity doesn't disappear—it no longer lives in engineers' heads.
The timing is right
Three major tailwinds make adaptive infrastructure possible today.
AI capabilities have crossed a critical threshold
Recent AI breakthroughs signal a fundamental shift in what's possible for infrastructure automation. OpenAI’s o3 model demonstrates abstract reasoning, scoring 87.5% on ARC-AGI, almost triple o1. That same capability enables understanding of how complex systems behave, fail, and adapt. Combined with distillation techniques that create specialized models for specific tasks, state-of-the-art LLMs can automate decisions in highly dynamic environments.
These systems can internalize complex institutional knowledge: your architecture, preferences, patterns, and goals. This allows them to not just automate tasks, but learn how you run infrastructure.
In practice, much of infrastructure today relies on trial-and-error: choose a configuration, deploy, check for errors, adjust accordingly. AI systems can execute this same pattern orders of magnitude faster, analyzing real-time data to iterate continuously. Unlike humans, these systems have unbounded memory and can learn from every past action and outcome, applying those insights to self-correct at scale.
We're hitting the limits of human-scale infrastructure management
The traditional approach of tracking telemetry, setting alerts, defining thresholds, and relying on engineers to connect the dots simply doesn't scale. Systems emit more data than humans can parse, and we're deploying more services than ever. We've outgrown the old interface entirely.
Software development is accelerating—not just in speed, but in shape
AI is enabling far more people to create software while allowing individual engineers to ship more, faster. The result isn't just more software, it's more fragmented software. Where we once had a few broad platforms, we now have millions of small systems, each with its own lifecycle, deployment, and infrastructure footprint.
How we get there
To reach this destination, we need to work backward from production to intent, learning organizational patterns. The most valuable insights come from understanding how specific systems behave, how teams make decisions, and which tradeoffs organizations actually prioritize.
Each step in this progression serves two purposes: solving immediate problems while building a deeper understanding of an organization's infrastructure DNA. The goal is to encode knowledge that typically lives only in senior engineers' heads.
Step 1: Automate incident response
Start with incident response, where both pain and knowledge are most concentrated. When systems fail, automate the debugging workflow and pull signals across observability data, source code, documentation, team communications, and deployment histories to surface likely root causes.
Incidents reveal the optimization boundary of infrastructure. Each failure provides insight into which components consistently cause problems and what constraints systems actually operate under. This maps the real optimization landscape: the specific pain points that matter most in each environment.
Step 2: Shift from reactive to proactive
With deep understanding of how failures happen, systems can recognize the early warning patterns teams have learned to watch for. Dynamic baselines can be established for every component, tracking leading indicators: database connection pools approaching capacity, memory consumption climbing steadily, API response times gradually increasing before failures cascade.
Real-time dependency graphs can show how failures propagate through specific architectures, predicting blast radius and preventing cascades. Each successful prediction refines the system's understanding of failure signatures unique to that environment.
Step 3: Optimize before deployment
Once failure patterns are understood, systems can model behavior before changes are deployed. Code changes can be analyzed for operational impact using everything learned: estimating database query performance based on your actual load patterns or modeling API payload changes against your real traffic profiles.
Before provisioning resources, the system can simulate performance using resource usage patterns and dependency relationships to assess deployment risk.
Step 4: Intent-driven infrastructure
The final step is infrastructure that responds directly to business goals. When teams say "make sure data retrieval is fast," the system translates that using everything it has learned about the organization's workloads, resource patterns, and failure modes. Infrastructure continuously monitors whether goals are being met and adapts accordingly.
Each step builds on what was learned before. The result is infrastructure that automates organization-specific approaches to infrastructure decisions. It's institutional knowledge that doesn't walk out the door and becomes more precise as your systems evolve.
From assistance to automation
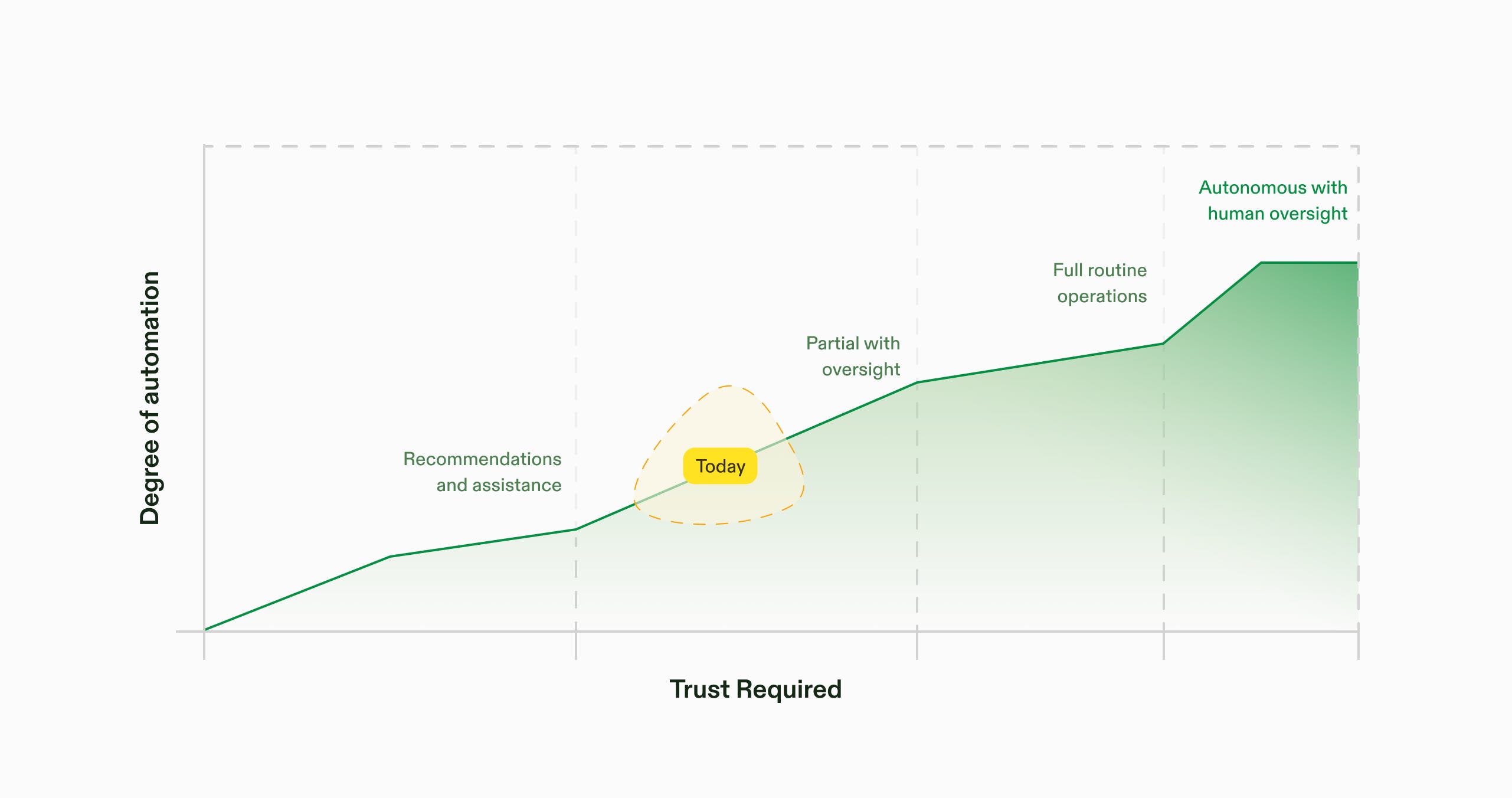
The transition to outcome-centric infrastructure isn't just a technical leap—it's a cultural one. Engineers don't hand over control lightly, and they shouldn't.
Trust has to be earned over time.
Initially, these systems should assist: suggesting likely causes, highlighting anomalies, and recommending actions with full investigative trails. Engineers stay in control.
But the system watches what you do. Which alerts get acted on? What fixes get trusted? Which recurring issues are ignored? These choices shape how the system evolves. It doesn't enforce a new way to work—it adapts to how you work, becoming more useful with each observation.
As confidence grows through repeated acceptance, low override rates, or explicit approval, it begins automating certain actions, saving time without sacrificing control. Instead of prescribing rules, systems learn them. Instead of enforcing processes, they reflect organizational preferences.
The goal isn't to replace engineers—it's to capture and scale their best judgment. To make that knowledge reusable and eliminate the maintenance that gets in the way of building.
Earning trust is the bridge to invisible infrastructure.
What becomes possible
The core outcome is simple: engineers can focus on building, not managing infrastructure complexity.
This unlocks entirely new possibilities. Two-person startups can deploy globally with the operational sophistication of a Fortune 500 company. Enterprise teams can experiment with infrastructure configurations that would've previously been too risky to attempt. Companies can maintain hundreds of microservices without proportionally scaling their ops teams.
But the deeper transformation is about knowledge itself. When institutional knowledge becomes embedded, it compounds. New engineers inherit years of operational wisdom on day one. The team's best debugging knowledge stays, even as people come and go. The constraint shifts from "can we keep this running?" to "what should we build next?"
This is what we're working toward. A future where complexity doesn't limit who gets to use technology.
Where infrastructure becomes invisible.